

はじめに
PythonでPDFを操作する方法を知っていますか?
PyPDF2を使うと、PDFの読み込み、結合・分割、テキストの抽出などが簡単に行えます。本記事では、PyPDF2の基本的な使い方を分かりやすく解説します。
やりたいこと
1.PDFを読み込んでページ数を取得する
2.複数のPDFを結合・分割する
3.PDFからテキストを抽出する
準備するもの
ライブラリ
インポート手順
PyPDF2を使用するには、まずライブラリをインストールしましょう。
pip install pypdf2ライブラリの説明
PyPDF2はPythonでPDFを操作するためのライブラリで、ページの読み込み、結合、分割、テキスト抽出などの機能を提供します。
ディレクトリ構成
以下のようなディレクトリ構成を想定しています。
project/
│── input.pdf # 読み込むPDFファイル
│── output.pdf # 出力するPDFファイル
│── merge_pdfs.py # PDFを結合するスクリプトコードスクリプト
ここでは、PDFを結合するスクリプトを紹介します。
PDFを結合するスクリプト
このスクリプトでは、PdfMerger を使って複数のPDFを結合します。
merge_pdfs 関数にPDFファイルのリストを渡し、結合されたPDFを作成します。
以下2つのPDFファイルを同じ階層に用意しております。
input1.pdf
input2.pdf
erge_pdfs.py
from PyPDF2 import PdfMerger
def merge_pdfs(pdf_list, output):
merger = PdfMerger()
for pdf in pdf_list:
merger.append(pdf)
merger.write(output)
merger.close()
print("PDFを結合しました!")
if __name__ == "__main__":
merge_pdfs(["input1.pdf", "input2.pdf"], "merged.pdf")
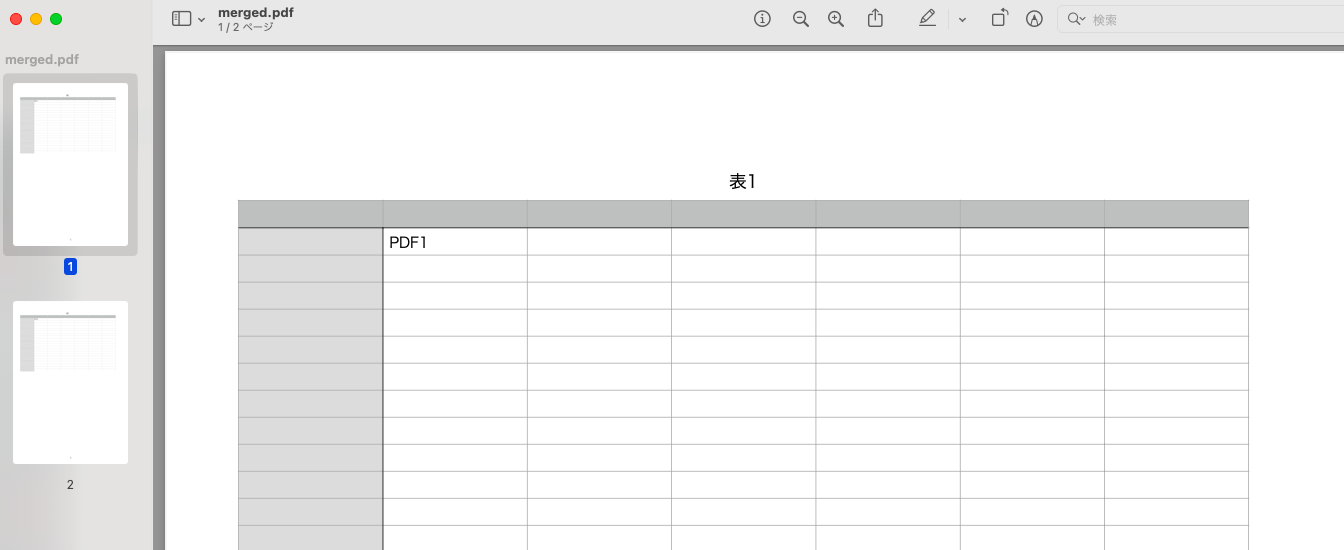
実行結果
PDFを結合しました!と表示され、フォルダ内に結合されたmarged.pdfが作成されました。
コード解説
PdfMergerを使用してPDFを結合。merger.append(pdf)で各PDFを追加merger.write(output)で新しいPDFを作成。if __name__ == "__main__"でスクリプトを実行。
注意点
- PyPDF2では、一部のPDFでテキストが正しく抽出できないことがあります。
- 画像ベースのPDFはOCRを使用しないとテキスト抽出ができません。
- 暗号化されたPDFを扱う場合、パスワード解除が必要です。
まとめ
本記事では、PyPDF2を使ってPDFの基本的な操作を学びました。
PdfMergerでPDFを結合するPdfReaderでPDFからテキストを抽出する
これらの機能を活用して、PythonでのPDF操作をぜひ試してみてください!


コメント